
Want to Run Your LLM? Here’s the Hidden Cost You Need to Know
In this blog, I share when to consider running your LLM and what are the hidden costs. Then I shared how to install DeepSeek locally in 5mins.

Want to run your own LLM? Here's when it makes sense and when it doesn't, and the hidden costs you need to know.
In my previous post, I shared how to install DeepSeek on your local machine for experimentation and evaluation. Now the question is "what's the real cost of running an in-house LLM?"
When I first explored running an in-house LLM, I was surprised by the operational costs such as energy consumption and expenses of GPU usage.
Here is a breakdown of when it makes sense to run your own LLM:
✅ High-volume API usage: If your company makes millions of API calls per month, API fees can go high significantly. Then running an LLM in-house might become cheaper in the long run.
✅ Existing Infrastructure: If your company has GPU infrastructure for existing AI/ML tasks, adding an LLM might not be an issue.
✅ Continuous API Costs: OpenAI and all other APIs charge per request. If an in-house model can handle the same workload efficiently, it eliminates these ongoing fees.
Don't run your own LLM if you want to prevent:
❌ Expensive hardware & cloud costs: Renting high-end GPUs from AWS, Azure, or GCP can be very expensive. On-premises GPUs require large upfront costs and maintenance.
❌ Operational complexity: Managing updates, security patches, and scaling the model requires an in-house team. API providers handle this for you at no extra cost.
❌ Energy consumption: Running an LLM 24/7 has huge electricity and cooling costs, which businesses might not consider in the first place.
Let's explore an example here:
If you want to run your own LLM on AWS Cloud, you need to use a GPU instance that can handle high-volume API calls. So the approximate costs will be as below.
Note: I included two instances one for only running LLM and one for running and fine-tuning tasks.
In the table below I compared three AWS GPU instances costs for only running LLM or for combined LLM and fine-tuning tasks. As you can see the cost of usage increase three times if you have high volume API usage from ~$547 to $1470 and if you additionally want to run fine-tuning, it costs $17870.
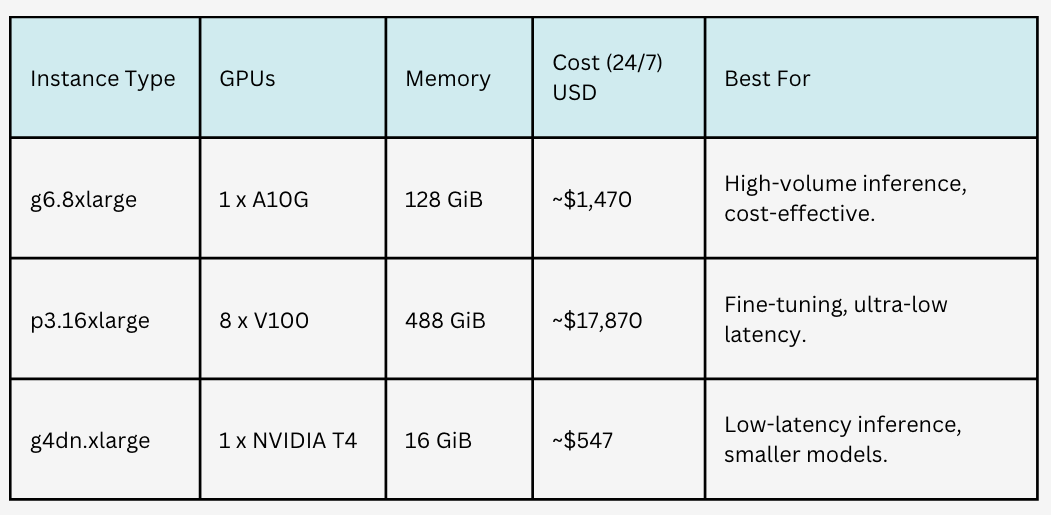
As you can see the cost is high significantly for running one GPU instance to handle API calls to an in-house LLM.
What’s your decision on running in-house LLMs? Comment below or DM me to discuss this further.
Run DeepSeek locally in 5 mins
If you want to control and customize your LLM, here is a quick guide to install DeepSeek locally. This will allow you to experiment with and own your LLM for future use.
In this guide, you will learn:
🔹DeepSeek model comparisons
🔹Install Ollama
🔹Run DeepSeek-R1 on Ollama
🔹 Run DeepSeek-R1-Distill-Qwen-1.5b (Faster and Smaller) on Google Colab
DeepSeek Models Comparison

Steps to Run DeepSeek-R1 On Ollama
Install Ollama (if you haven’t already)
For Linux users:

Other OS: Download Ollama here.
For Mac users:


Pull Deepseek-R1

Once Ollama is installed, open the Command Line Interface (CLI) and pull the model:





Run the model
Now you can run the model

Once the model is available, you can ask any questions and it will reply you with no issue.

Steps to Run DeepSeek-R1-Distill On GoogleColab
Go to Google Colab
a. Create a new notebook
b. Set the Runtime to GPU/TPU by choosing Runtime type(GPU is generally recommended)
Install Python libraries
In the new notebook, run the following command

Download and load the Deepseek model
Now you can download and load the model and run some experiment.

Check this out and comment below or DM me if you need assistance with production use cases.